How to Organize Research Papers and Streamline Your Workflow
Organizing research papers isn't just about tidying up your computer; it’s about moving from a passive file-hoarder to an active knowledge manager. A good system is built on a few core ideas: a logical folder structure, consistent metadata tagging, and smart tools like Eagle Cite that can automate the heavy lifting of search and discovery. This is how you transform a chaotic pile of PDFs into a library you can actually use.
Conquering the Chaos of Academic Research

We've all been there: a desktop littered with cryptically named PDFs, a downloads folder overflowing with duplicates. Those old-school methods just don't cut it anymore. The sheer volume of new research published every year makes it impossible to keep up, leading to wasted time and rediscovered work. That constant influx of information can quickly turn your digital workspace into a source of stress.
This isn't just a feeling; the numbers back it up. In 2022 alone, researchers published around 3.3 million articles worldwide. That's a stunning 59% jump from just a decade earlier. You can see the full analysis of this publication surge on ncses.nsf.gov to really grasp the scale of the challenge. This data makes one thing crystal clear: a systematic approach to organization is no longer a "nice-to-have"—it's a fundamental requirement for staying afloat.
Why a System Is Your Greatest Asset
A well-designed organization system does so much more than keep your files neat. It builds a direct bridge between a research question and its answer, letting you find the exact paper you need in seconds, not hours. The real goal is to move beyond simple storage and create a personal, searchable knowledge base that evolves with your work.
This requires a slight shift in thinking. Instead of viewing each paper as an isolated document, you start seeing it as a node in your personal network of ideas. Your organization system is the scaffolding that connects these nodes, helping you spot patterns and relationships you might have otherwise missed. It’s the difference between having a pile of bricks and a finished building.
The most important thing is that you build your own system. You have to own it. You might find it easier to adopt someone else’s system, but you should be intentional about every habit you acquire. Be prepared to iterate.
Ultimately, an effective strategy underpins the entire research lifecycle. It's not just about filing things away; it's about making your resources useful for the long haul. This foundation streamlines everything that follows, from conducting a literature review to drafting a manuscript. By learning how to organize research papers now, you’re investing in a more efficient and productive future.
A great first step in this whole process is mastering how you consume the information in the first place. For more on that, check out our guide on how to read scientific papers effectively.
Before we dive into the "how," let's quickly summarize the core components of a modern, organized research library. These are the pillars that support a functional and scalable system.
Key Pillars of an Organized Research Library
| Pillar | Objective | Key Action |
|---|---|---|
| Structure | Create a logical and predictable home for every paper. | Design a hierarchical folder system based on projects or broad themes. |
| Metadata | Make papers discoverable based on their content, not just their file name. | Apply consistent tags, keywords, and ratings to each document. |
| Searchability | Find any paper, concept, or piece of data instantly. | Use tools that offer full-text search and filter by your metadata. |
| Collaboration | Share and manage research papers with colleagues seamlessly. | Establish a shared library with standardized tagging and access rules. |
With these pillars in mind, you can start building a workflow that prevents digital clutter and puts your knowledge to work.
Building Your Digital Library Foundation
Before you get into the fancy software and tagging systems, you need a solid digital 'bookshelf.' This is the bedrock of your whole organization system—a predictable, logical home for every single paper you collect. A well-thought-out folder structure makes your library make sense from the moment you start building it.
Too many of us begin with generic folders like "Papers" or, even worse, just leave everything in "Downloads." That's a surefire way to create a digital junk drawer. A much better way is to organize your library around how you actually work. Think in terms of projects, courses, or thesis chapters. This method naturally aligns with your research process, so you'll instinctively know where to find and save things.
This is what a clean, project-based folder hierarchy and a standardized file naming system look like in practice.
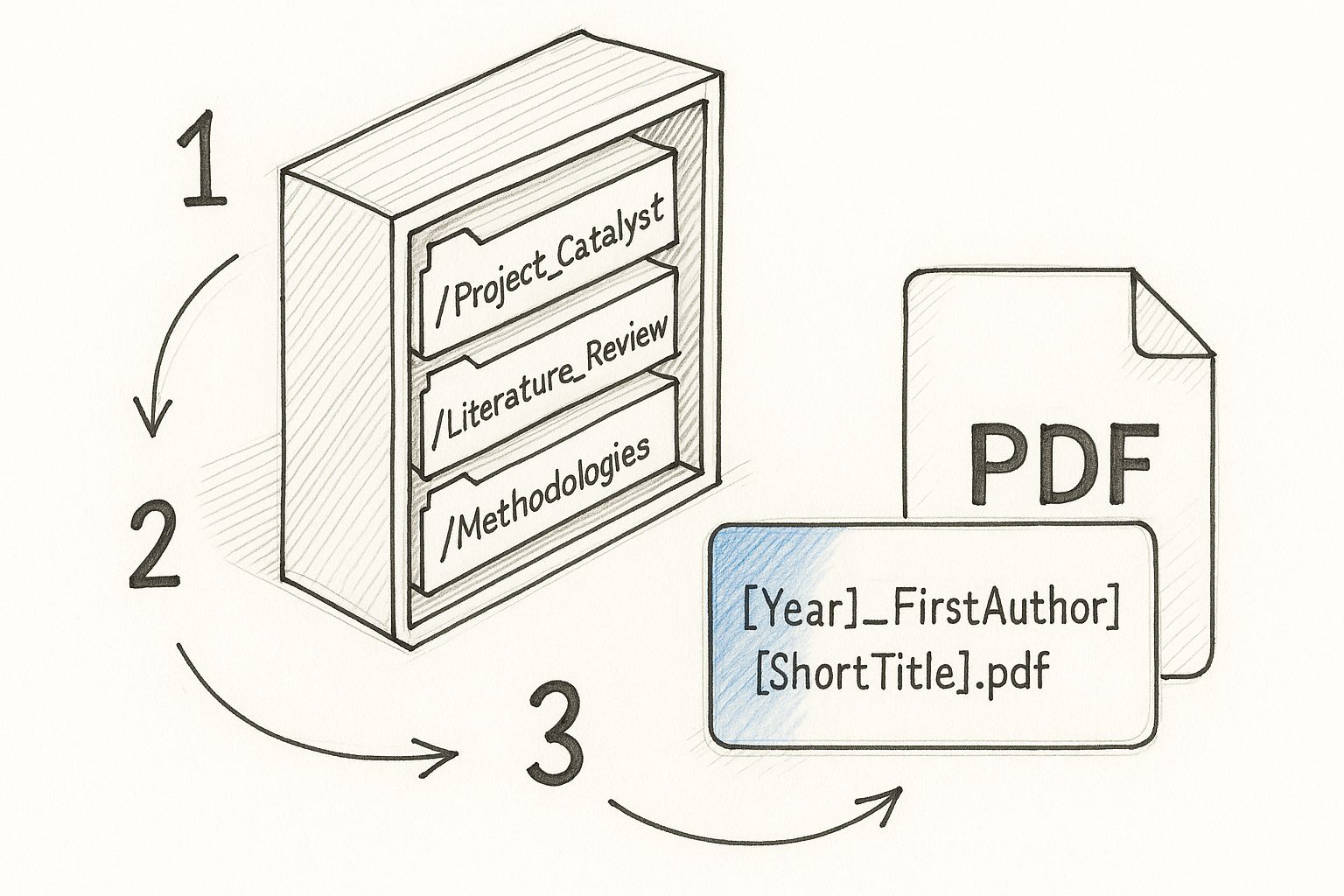
When you see it laid out, it's clear how a logical structure keeps chaos at bay. Every piece of research has a home from the second you save it.
Design a Scalable Folder Structure
Your top-level folders should be the big-picture categories of your work. This gives you a clean, high-level map of your entire research world.
- /Project_Catalyst/ for your main research project.
- /Thesis_Chapters/ for everything related to your dissertation.
- /Coursework_Fall2024/ for papers and readings for a specific class.
- /General_Reading/ for those interesting articles you find that aren't tied to a current project.
From there, you can nest subfolders for more detail. Inside /Project_Catalyst/, for example, you might create /Literature_Review/, /Methodologies/, and /Data_Analysis/. This level of detail means you can drill down to find specific resources without having to rely on search every time. And while a good tool is essential, understanding the importance of a reference manager really starts with appreciating the solid structure it's built on.
Implement a Consistent File Naming Convention
If there's one habit that will pay off massively, it's a disciplined file naming system. It makes your files identifiable at a glance, even when you're looking at them outside your reference manager. A huge part of a functional digital library is setting up clear file naming conventions best practices right from the start.
I’ve found that a simple but incredibly effective formula is: [Year]_[FirstAuthor]_[ShortTitle].pdf
For instance, a paper by Dr. Eleanor Vance from 2023 on quantum computing would become 2023_Vance_QuantumEntanglement.pdf. This format is brilliant because it automatically sorts your files chronologically and tells you exactly what they are.
This one small, consistent action saves you from the future nightmare of trying to make sense of useless filenames like download(1).pdf or S0140-6736(21)02796-0.pdf. By putting a logical folder structure and a standardized naming convention together, you build a powerful foundation that stays organized and can handle a growing collection of papers. This groundwork is what sets you up for success with more advanced organization techniques down the road.
Supercharging Your System with Smart Tagging
A logical folder structure is a great starting point, but let’s be honest—it’s only half the battle. Folders are rigid. A single paper can only live in one place, but its ideas? They connect to everything. This is where smart tagging comes in, breaking down those digital walls and turning your static library into a fluid, interconnected web of knowledge.
I like to think of it like this: folders are the bookshelves, but tags are the cross-referenced index cards that tell you everything about the book, not just where it sits. This multi-layered approach is how you truly unlock the power of your research collection.
As you can see, a tool like Eagle Cite lets you easily apply a whole bunch of descriptive tags to a single paper. This means you can slice and dice your library in countless ways, instantly pulling together related research that might be buried in completely different project folders.
Creating a Multi-Layered Tagging Strategy
Don't just pull generic keywords from the abstract. The real power comes from building a personalized tagging system that mirrors how you actually think and work. It makes finding what you need later incredibly intuitive.
Your system should have a few different kinds of tags, each serving a distinct purpose. Here are some of the categories I’ve found most useful over the years:
Methodology Tags: These tell you how* the research was done. Thinkqualitative-study, RCT (for Randomized Controlled Trial), longitudinal-data, or meta-analysis. This is a lifesaver when you need to find all studies using a specific approach.
- Theoretical Framework Tags: These capture the big ideas. You might use tags like
actor-network-theory,cognitive-dissonance, orgame-theoryto group papers by the concepts they explore. - Project Relevance Tags: This is my favorite. Link papers directly to your active work. Get specific with tags like
Project_Catalyst_Corefor the absolute must-reads orThesis_Chapter_2_Backgroundfor literature tied to a particular section. - Workflow Status Tags: Keep track of where you are in the reading process. Simple, action-oriented tags like
to-read,reading-in-progress,summarized, andcited-in-draftcan save you a ton of mental energy.
The real payoff is when you combine these tags. You can instantly find every paper tagged with
RCTandProject_Catalyst_Corethat you still have marked asto-read. That kind of granular control is something you'll never get from a folder-only system.
Putting Your Tagging System into Practice
The secret to making any tagging system work is consistency. Spend a little time upfront deciding on your main categories and then stick to them. A good reference manager makes this a breeze by letting you create, manage, and even apply tags in batches.
This is where the magic really happens. All of a sudden, you're not just looking for a file; you’re querying your own personal research database. Need to find every single qualitative study you've ever saved for a specific project? A couple of clicks, and they’re all right there, no matter which folder they’re in. It fundamentally changes how you interact with your library, turning a passive collection into an active, intelligent research partner.
Using AI for Intelligent Search and Discovery
Once you have a well-organized library, the real magic begins. You can finally stop scrolling through endless folders and let technology do the heavy lifting. Modern tools packed with artificial intelligence can search far beyond just filenames and keywords, digging right into the content of your papers to pull out exactly what you need in seconds.
This completely changes the game. Instead of wrestling with complex Boolean search terms, you can just ask a question in plain English. With tools like Eagle Cite, you can type something like, "Find recent papers on CRISPR for gene editing," and the AI gets it. It understands what you mean and pulls up relevant articles, even if they don't use those exact words in the title. It’s a huge step toward making academic search feel more natural.
Uncovering Hidden Connections in Your Research
One of the best things about using AI is its knack for finding connections you might have missed completely. A perfect example of this is citation chaining. You find one key paper in your library, and with a single click, you can instantly pull up two incredibly useful lists:
- All the newer papers that have cited that work.
- All the older papers that work was built on.
Suddenly, you have an intellectual roadmap. You can trace an idea back to its roots or jump forward to see how it’s evolving today. I’ve found this is one of the fastest ways to get up to speed in a new field and make sure my literature review is solid.
Intelligent search isn't just about finding papers faster; it's about finding the right papers that you didn't even know you were looking for. It surfaces related concepts and adjacent research, adding depth and robustness to your work.
From Text to Actionable Insights
AI’s usefulness doesn't stop with PDFs. Research today is all over the place—you might have interview recordings, video presentations, or raw datasets in your library. To get the most out of these, understanding a bit about what audio transcription is can be a huge help, allowing AI to search the spoken content of your media files, too.
This way of working also fits right in with where academia is headed. A 2020 survey showed that most researchers want open access to journal content, which means we’re not just managing PDFs anymore. We're dealing with shared data and different versions of articles. You can discover more insights about these research trends on pmc.ncbi.nlm.nih.gov.
Bringing AI search into your workflow helps you wrangle all this complexity, making your entire knowledge base searchable, no matter the format. When you learn how to organize research papers with these tools, you're not just building a library; you're creating a dynamic system that actually speeds up your next discovery.
Working Together Without the Headaches
Research is almost never a solo mission. It’s a team sport, often played across different labs, universities, and sometimes even continents. But the moment you start sharing files, a messy library can turn into absolute chaos. The real trick to organizing research papers as a group isn't just about folders; it's about building a single, shared brain that everyone can tap into without confusion.
We've all been there. You end up emailing PDFs back and forth, creating a nightmare of different versions and wasted effort. What happens to that perfect folder system you built when your collaborator can't even see it? This is exactly why a central, cloud-based library is essential for any modern research team.
Setting Up Your Team's Command Center
First things first: you need one shared space for every paper, every note, and every scribbled annotation. This is precisely what tools like Eagle Cite are designed for. You can create a shared library that stays in sync for the entire team, finally putting an end to the "who has the latest version?" scavenger hunt.
Before you send out the invites, it's wise to agree on some ground rules. This isn't about bureaucracy; it's about making sure the system works for everyone. A quick chat to agree on a few basics can save you countless hours down the road.
Project Folders are a Must: Create a main folder for each major project. This simple step prevents the literature for your study on C. elegans* from getting mixed up with the papers for your quantum computing review.- Decide on Permissions: Figure out who can add, edit, or just view files. This is a lifesaver in larger labs, especially when you have students or assistants cycling through.
- Agree on a Common Language for Tags & Notes: Settle on a core set of tags your team will use and a consistent way to leave notes or highlights.
Here's a pro-tip: Make a simple rule like, "Every new highlight needs a comment explaining why it's important." This one change transforms passive reading into a dynamic, team-wide conversation right inside the document.
A shared system like this is no longer a luxury, especially as research becomes more and more global. In 2022, a staggering 23% of all scientific articles involved international coauthors. That figure jumps to 67% in places like the United Kingdom. When your collaborators are in different time zones, a synchronized library is the only thing keeping the project moving forward. You can see the full breakdown of these collaboration trends on the NSF's website.
Avoiding Redundancy and Crossed Wires
With your shared library in place, the next challenge is keeping things clear day-to-day. One of the biggest time-sinks for any research team is accidentally doubling up on work. There’s nothing more frustrating than finding out two people spent hours summarizing the exact same foundational paper.
This is where a shared workflow comes in. Using a simple set of status tags—like the to-read, summarizing, and completed tags we talked about earlier—gives everyone an instant snapshot of who’s doing what. This kind of transparency means you're coordinating your efforts, not just duplicating them. When you build these habits, your organized library stops being a simple file cabinet and becomes the engine that powers your team’s progress.
An organized library is a living thing, not a one-time setup you can just forget about. If you want to keep your carefully built system from sliding back into chaos, the secret is all about building small, consistent habits. Think of it less like a massive chore and more like simple digital housekeeping.
The single most effective habit I’ve ever picked up is a weekly "review and file" session. I carve out just 15 minutes every Friday afternoon to handle any new papers I’ve downloaded throughout the week. That’s all it takes to assign the right filename, drop it into the correct project folder, and add the most important tags. This tiny investment of time completely stops a backlog from ever forming.
Keep Your Workspace Focused and Current
As you finish up projects, your active library can start feeling cluttered with research you don't need at your fingertips anymore. A great way to handle this is to archive old work. I just have a main "Archive" folder, and when a project is done, I move its entire folder (like /Project_Catalyst/) right into it. This keeps my day-to-day workspace clean and focused on what's active, but I can still easily dig up old materials if I need them.
Your organization system isn't set in stone; it should evolve right alongside your research. Don't hesitate to tweak your tags or adjust your folder structure as your focus changes. The system that worked perfectly for your dissertation might need a few changes for that new grant proposal you're working on.
Finally, make it a point to review your tagging system every so often. Are the tags you created last year still relevant? Have you branched into new research areas that need their own categories? A quick yearly audit ensures your system is still working for you, not against you. This becomes especially important when you're balancing different roles and studies. For more on that, check out our guide on how to manage multiple projects.
Got Questions? Let's Clear Things Up
Even the best-laid plans run into a few snags. As you start to organize your research papers, you’ll naturally have questions. Here are a few of the most common ones I hear, along with some practical advice to keep you moving forward.
What’s the Best Reference Manager to Start With?
If you're just dipping your toes in, you can't go wrong with Zotero. It’s free, open-source, and packed with enough features to build solid organizational habits without spending a dime. It's a fantastic starting point.
But what if you're a visual thinker? Or if your work demands powerful AI search and easy collaboration? That’s where a more integrated tool like Eagle Cite really shines. The "best" choice honestly comes down to your personal workflow, budget, and how complex your projects get. My advice? Start free to learn the fundamentals, then consider upgrading when you feel your current tool is holding you back.
How Do I Handle Files That Aren't PDFs, Like Datasets or Slides?
This is a great question because research is so much more than just papers. Your system has to account for everything—datasets, presentation slides, manuscripts, interview transcripts, you name it. The goal is to keep all related materials together.
An easy way to do this is by creating specific subfolders within your main project folder, like Data, Slides, or Manuscripts.
A real game-changer is when your tool can handle this internally. For example, with Eagle Cite, you can drop different file types right into your library. This means you can use the same smart tags on a dataset that you use on a paper, making the link between them instantly searchable.
Is It Really Worth the Effort to Organize All My Old Papers?
Yes, absolutely—but don't try to do it all at once. That's a recipe for burnout. The biggest mistake people make is trying to tackle a backlog of hundreds, or even thousands, of papers in one weekend. It's just not sustainable.
Instead, be strategic. Here's a much more manageable approach that I’ve seen work time and time again:
- Rule #1: From this moment on, every new paper you download goes into your new system. No exceptions.
- For the old stuff: Create a single folder called
_Archive_ToBeSortedand dump your entire backlog in there. - Now, here's the trick: only organize an old paper when you actually need it for a current project. When you pull it out of the archive, process it properly.
- If you find yourself with a spare 15 minutes, you can chip away at the archive. But don’t let it become a source of stress.
This way, your most relevant past research gets integrated into your new library organically, without the overwhelming pressure of a massive cleanup project.
Ready to stop searching and start discovering? Transform your research workflow with Eagle Cite. Start your free 14-day trial today and build a smarter research library.